Spark Streaming and Kafka Integration Example
Spark Streaming and Kafka Integration Example
Introduction
My search online for a good tutorial on Big Data processing using Spark Streaming and Kafka ended up in a bunch of old posts which had very old versions of Spark and Kafka client libraries. They were of no use to me if I wanted to use the newer versions of the libraries. Hence I decided that I should share my experience with the newer versions of the libraries. This was the motivation for me to come up with this post. This post will give you a comprehensive overview of Spark Streaming and Kafka Integration. The use case that I am trying to address in this post is to process streaming data from a topic on Kafka using Spark Streaming. This is a very common use case that many organizations large and small are implementing these days.
I will be presenting 2 examples in this post. One example will print the stream of data from a Kafka Topic as it receives it and the other example counts the occurrences of a word from a stream of data from a Kafka topic. I have used Scala for coding these 2 examples. So lets get started.
I will be presenting 2 examples in this post. One example will print the stream of data from a Kafka Topic as it receives it and the other example counts the occurrences of a word from a stream of data from a Kafka topic. I have used Scala for coding these 2 examples. So lets get started.
Spark Streaming
Spark Streaming is a streaming data processing framework which is primarily used for real-time data analytics. Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Spark Streaming is widely being used today as Real-time data processing and analytics have become a critical component of the big data strategy for most organizations.
Some of the use cases and organizations where Spark Streaming is being used are:


1. The main class takes in 2 program arguments which are of type String and are: Kafka Brokers and Kafka Topics. Here is the code used for this:
1. The main class takes in 2 program arguments which are of type String and are: Kafka Brokers and Kafka Topics. Here is the code used for this:
Some of the use cases and organizations where Spark Streaming is being used are:
- Fraud Detection in many different industries including banking and financial sectors, insurance, government agencies and law enforcement, and more
- Supply Chain Analytics
- Real-time telemetry analytics (Uber)
- Analytics in E-Commerce websites (Amazon, Flipkart)
- Real-time video analytics in many of the video streaming platforms (Netflix)
- Predictive Risk & Compliance in many financial organizations
- Live Flight Optimization in the airline industry (United Airlines)
- Continuous Transaction Optimization in banking industry (Morgan Stanley)
- IoT Parcel Tracking in postal and logistics organizations (Royal Mail, UK)
- Live Train Time Tables (Dutch Railways)
Here is a pictorial overview of Spark Streaming (Source: Apache Spark Website)


You can read more about Spark Streaming at the Apache Spark Website.
Kafka
Kafka is a distributed streaming platform. It can be used for communication between applications or micro services. Kafka is ideally used in big data applications or in applications that consume or process huge number of messages.
Some use cases where Kafka can be used:
- Messaging
- Website activity tracking
- Metrics
- Log aggregation
- Stream processing
- Event sourcing
- Commit log
Few Advantages of Kafka:
- Horizontally scalable
- Fault-tolerant
- Very fast
- Tried, tested and used by many organizations in production.
A few very important concepts are to be known when using Kafka.
- Kafka is run as a cluster on one or more servers.
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
More details about Kafka can be read from their website.
- Intellij IDE with SBT and Scala Plugins
- Kafka
Kafka should be setup and running in your machine. To setup, run and test if the Kafka setup is working fine, please refer to my post on: Kafka Setup.
In this tutorial I will help you to build an application with Spark Streaming and Kafka Integration in a few simple steps.
In this tutorial I will help you to build an application with Spark Streaming and Kafka Integration in a few simple steps.
Step 1: Dependencies in build.sbt
Since the code is in Scala, I will be using sbt for build related setup. sbt (Scala Build Tool, formerly Simple Build Tool) is an open source build tool for Scala and Java projects, similar to Java's Maven and Ant. I am using the following in this tutorial:- Scala Version = 2.11.8
- Spark Version = 2.2.0
- Kafka Client Version = 0.8.2.1
These have to be set in the file: build.sbt
Here is the full build.sbt:
name := "SparkKafka"
version := "1.0"
organization := "com.aj"
scalaVersion := "2.11.8"
scalacOptions := Seq("-deprecation", "-unchecked", "-encoding", "utf8", "-Xlint")
libraryDependencies ++= {
val sparkVersion = "2.2.0"
val kafkaClientVersion = "0.8.2.1"
Seq(
"org.apache.spark" %% "spark-core" % sparkVersion,
"org.apache.spark" % "spark-streaming_2.11" % sparkVersion,
"org.apache.spark" % "spark-streaming-kafka-0-8_2.11" % sparkVersion,
"org.apache.spark" %% "spark-sql" % sparkVersion,
"org.apache.spark" %% "spark-hive" % sparkVersion,
"org.apache.spark" %% "spark-repl" % sparkVersion,
"org.apache.kafka" % "kafka-clients" % kafkaClientVersion
)
}
Step 2: Main Object
Example One: Print stream of data from a Kafka Topic
Main Object is the Main Class and entry point of the application. Here is the code for SparkKafkaStream.scala:
package com.aj.sparkkafka
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object SparkKafkaStream {
def main(args: Array[String]) {
if (args.length != 2 ) {
System.err.println("Please pass program arguments as: <brokers> <topics>")
System.exit(1)
}
val Array(brokers, topics) = args
val sparkConf = new SparkConf().setAppName("SparkKafkaStream").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(10))
//Get the Kafka Topics from the program arguments and create a set of Kafka Topics
val topicsSet = topics.split(",").toSet
//Set the brokers in the Kafka Parameters
val kafkaParameters = Map[String, String]("metadata.broker.list" -> brokers)
//Create a direct Kafka Stream using the Kafka Parameters set and the Kafka Topics
val messagesFromKafka = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParameters, topicsSet)
//Get the lines
val lines = messagesFromKafka.map(_._2)
//Print
lines.print()
//Save to Text Files
val outputLocation = "output/sparkkafkastream"
lines.saveAsTextFiles(outputLocation)
ssc.start()
ssc.awaitTermination()
}
}
I have put the comments for most of the lines of code above to describe what the code does. Here is an overview of the things being done in the code above:1. The main class takes in 2 program arguments which are of type String and are: Kafka Brokers and Kafka Topics. Here is the code used for this:
def main(args: Array[String]) {
if (args.length != 2 ) {
System.err.println("Please pass program arguments as: <brokers> <topics>")
System.exit(1)
}
2. For this program to run as a stand alone application, a new Spark Config needs to be created. SparkConf API represents configuration for a Spark application. It is used to set various Spark parameters as key-value pairs. I am setting App Name and Master parameters to it. Then a new Spark Streaming Context needs to be created. StreamingContext API is the main entry point for Spark functionality. A SparkContext represents the connection to a Spark cluster and can be used to create RDDs, accumulators and broadcast variables on the spark cluster. If you observe the code below I am creating a streaming context with an interval of 10 seconds. Hence it will check for data from the Kafka topic every 10 seconds. Here is the code for this:val sparkConf = new SparkConf().setAppName("SparkKafkaStream").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(10))
3. Then I create a direct Kafka Stream using the Kafka Parameters that I have set and the Kafka Topics passed as input parameters://Get the Kafka Topics from the program arguments and create a set of Kafka Topics
val topicsSet = topics.split(",").toSet
//Set the brokers in the Kafka Parameters
val kafkaParameters = Map[String, String]("metadata.broker.list" -> brokers)
//Create a direct Kafka Stream using the Kafka Parameters set and the Kafka Topics
val messagesFromKafka = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParameters, topicsSet)
4. Print messages from the Kafka Topic on the console and the output directory location://Get the lines val lines = messagesFromKafka.map(_._2) //Print lines.print() //Save to Text Files val outputLocation = "output/sparkkafkastream" lines.saveAsTextFiles(outputLocation)5. Start and await termination of the Streaming Context created.
ssc.start() ssc.awaitTermination()
Example Two: Count and print the occurrences of a word from the stream of data from a Kafka Topic
Main Object is the Main Class and entry point of the application. Here is the code for SparkKafkaWordCount.scala:
package com.aj.sparkkafka
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object SparkKafkaWordCount {
def main(args: Array[String]) {
if (args.length != 2 ) {
System.err.println("Please pass program arguments as: <brokers> <topics>")
System.exit(1)
}
val Array(brokers, topics) = args
val sparkConf = new SparkConf().setAppName("SparkKafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(10))
//Get the Kafka Topics from the program arguments and create a set of Kafka Topics
val topicsSet = topics.split(",").toSet
//Set the brokers in the Kafka Parameters
val kafkaParameters = Map[String, String]("metadata.broker.list" -> brokers)
//Create a direct Kafka Stream using the Kafka Parameters set and the Kafka Topics
val messagesFromKafka = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParameters, topicsSet)
//Get the lines
val lines = messagesFromKafka.map(_._2)
//Split the lines into words
val words = lines.flatMap(_.split(" "))
//Count the words
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
//Print
wordCounts.print()
//Save to Text Files
val outputLocation = "output/sparkkafkawordcount"
wordCounts.saveAsTextFiles(outputLocation)
ssc.start()
ssc.awaitTermination()
}
}
I have put the comments for most of the lines of code above to describe what the code does. Here is an overview of the things being done in the code above:1. The main class takes in 2 program arguments which are of type String and are: Kafka Brokers and Kafka Topics. Here is the code used for this:
def main(args: Array[String]) {
if (args.length != 2 ) {
System.err.println("Please pass program arguments as: <brokers> <topics>")
System.exit(1)
}
2. For this program to run as a stand alone application, a new Spark Config needs to be created. SparkConf API represents configuration for a Spark application. It is used to set various Spark parameters as key-value pairs. I am setting App Name and Master parameters to it. Then a new Spark Streaming Context needs to be created. StreamingContext API is the main entry point for Spark functionality. A SparkContext represents the connection to a Spark cluster and can be used to create RDDs, accumulators and broadcast variables on the spark cluster. If you observe the code below I am creating a streaming context with an interval of 10 seconds. Hence it will check for data from the Kafka topic every 10 seconds. Here is the code for this:val sparkConf = new SparkConf().setAppName("SparkKafkaStream").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(10))
3. Then I create a direct Kafka Stream using the Kafka Parameters that I have set and the Kafka Topics passed as input parameters://Get the Kafka Topics from the program arguments and create a set of Kafka Topics
val topicsSet = topics.split(",").toSet
//Set the brokers in the Kafka Parameters
val kafkaParameters = Map[String, String]("metadata.broker.list" -> brokers)
//Create a direct Kafka Stream using the Kafka Parameters set and the Kafka Topics
val messagesFromKafka = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParameters, topicsSet)
4. Get the lines from the Kafka topic messages, split the lines into words, count the words and print the words and the corresponding count from the Kafka Topic on the console and the output directory location:
//Get the lines
val lines = messagesFromKafka.map(_._2)
//Split the lines into words
val words = lines.flatMap(_.split(" "))
//Count the words
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
//Print
wordCounts.print()
//Save to Text Files
val outputLocation = "output/sparkkafkawordcount"
wordCounts.saveAsTextFiles(outputLocation)
5. Start and await termination of the Streaming Context created.ssc.start() ssc.awaitTermination()
Step 3: Configure Logging
I am configuring the logging to print everything to the console. I am also adding a few settings to not log the third party logs that are too verbose. Here is the file log4j.properties:
# Log everything to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Settings to not log the third party logs that are too verbose
log4j.logger.org.eclipse.jetty=WARN
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
Run Application:
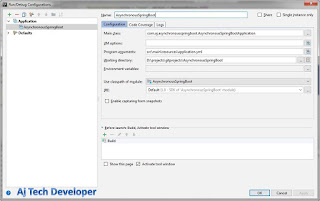
1. To run the SparkKafkaStream application in your IDE use:
Main class: com.aj.sparkkafka.SparkKafkaStream
Set Kafka Host and Port and Kafka Topic in program arguments. I have used the following:
Program Arguments: localhost:9092 softwaredevelopercentral

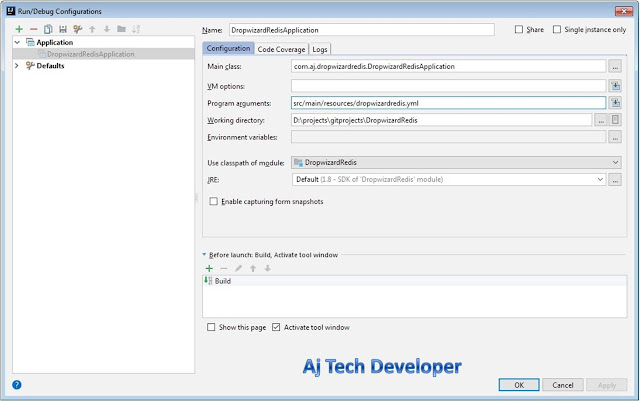
2. To run the SparkKafkaWordCount application in your IDE use:
Main class: com.aj.sparkkafka.SparkKafkaWordCount
Set Kafka Host and Port and Kafka Topic in program arguments. I have used the following:
Program Arguments: localhost:9092 softwaredevelopercentral

Results:
Zookeeper and Kafka should be running in your machine.
I have created a Kafka Topic softwaredevelopercentral and I am using it to send messages to the application. Here are the commands used in Kafka.
I have created a Kafka Topic softwaredevelopercentral and I am using it to send messages to the application. Here are the commands used in Kafka.
To create Kafka topic softwaredevelopercentral :
D:\Programs\Apache\kafka_2.11-0.11.0.0>bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic softwaredevelopercentralTo list the topics in Kafka
D:\Programs\Apache\kafka_2.11-0.11.0.0>bin\windows\kafka-topics.bat --list --zookeeper localhost:2181To send messages on the topic softwaredevelopercentral, start the producer
D:\Programs\Apache\kafka_2.11-0.11.0.0>bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic softwaredevelopercentral
1. SparkKafkaStream
Run the program in IDE and send messages from the Kafka topic. The messages are displayed on the console and in the output directory location.For the application SparkKafkaStream, the output location will be output/sparkkafkastream-NNNNNNNNNNNNN. You should find a _SUCCESS and a part-00000 file. Following Hadoop conventions, the latter contains the actual data for the "partitions" (in this case just one, the 00000 partition). The _SUCCESS file is empty. It is written when output to the part-NNNNN files is completed, so that other applications watching the directory know the process is done and it's safe to read the data.
Send messages on the Kafka topic softwaredevelopercentral


2. SparkKafkaWordCount
Run the program in IDE and send messages from the Kafka topic. The messages are displayed on the console and in the output directory location.For the application SparkKafkaWordCount, the output location will be output/sparkkafkawordcount-NNNNNNNNNNNNN. You should find a _SUCCESS and a part-00000 file. Following Hadoop conventions, the latter contains the actual data for the "partitions" (in this case two, the 00000 partition and the 00001 partition). The _SUCCESS file is empty. It is written when output to the part-NNNNN files is completed, so that other applications watching the directory know the process is done and it's safe to read the data.
Send messages on the Kafka topic softwaredevelopercentral


Conclusion and GitHub link:
In this post I have shown you how you can perform big data processing by using Spark Streaming with Kafka integration. The code used in this post is available on GitHub.
Learn the most popular and trending technologies like Machine Learning, Chatbots, Angular 5, Internet of Things (IoT), Akka HTTP, Play Framework, Dropwizard, Docker, Elastic Stack, Netflix Eureka, Netflix Zuul, Spring Cloud, Spring Boot, Flask and RESTful Web Service integration with MongoDB, Kafka, Redis, Aerospike, MySQL DB in simple steps by reading my most popular blog posts at Software Developer Central.
If you like my post, please feel free to share it using the share button just below this paragraph or next to the heading of the post. You can also tweet with #SoftwareDeveloperCentral on Twitter. To get a notification on my latest posts or to keep the conversation going, you can follow me on Twitter or Instagram. Please leave a note below if you have any questions or comments.
Learn the most popular and trending technologies like Machine Learning, Chatbots, Angular 5, Internet of Things (IoT), Akka HTTP, Play Framework, Dropwizard, Docker, Elastic Stack, Netflix Eureka, Netflix Zuul, Spring Cloud, Spring Boot, Flask and RESTful Web Service integration with MongoDB, Kafka, Redis, Aerospike, MySQL DB in simple steps by reading my most popular blog posts at Software Developer Central.
If you like my post, please feel free to share it using the share button just below this paragraph or next to the heading of the post. You can also tweet with #SoftwareDeveloperCentral on Twitter. To get a notification on my latest posts or to keep the conversation going, you can follow me on Twitter or Instagram. Please leave a note below if you have any questions or comments.

Comments
Post a Comment